
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- 프로그래머스
- 2800
- 이분탐색
- 골드5
- 그래프
- TouchableWithoutFeedback
- 백준
- 상담원 인원
- ReactNative
- 딥러닝
- useHeaderHeight
- 3079
- FlatList
- 그리디
- 복잡도 측정
- 자료구조
- PYTHON
- React #새파일생성
- 머신러닝
- LV3
- 큐
- 시간초과해결
- 이진탐색
- 실버1
- 11831
- 수정렬하기4
- 괄호제거
- 17089
- 브루트포스
- KeyboardAvoidingView
- Today
- Total
지니 코딩일기
[딥러닝/머신러닝] 머신 러닝, 딥 러닝이란 ? 본문
인공지능 (Artificial Intelligence, AI)은 인간과 유사한 지능을 갖는 컴퓨터 시스템을 의미하는 것으로, 데이터를 분석하고 패턴을 학습하여 추론, 결정, 문제 해결 등을 수행할 수 있다. 이러한 인공지능은 머신러닝, 딥러닝 등의 기술을 사용하여 구현된다.
머신러닝(Machine Learning, 기계 학습)은 인공지능의 하위 분야로, 컴퓨터가 데이터로부터 스스로 학습하고 패턴을 파악하는 알고리즘을 의미한다. 데이터와 알고리즘을 사용하여 인간이 학습하는 방식을 모방하고 점차 정확도를 향상하는 데 중점을 둔다. 컴퓨터 시스템이 스스로 지속적인 조정과 향상을 수행하도록 하므로, 데이터가 많을수록 더 정확한 결과를 얻을 수 있다.
딥 러닝(Deep Learning)은 머신러닝의 하위 분야로, 깊은 신경망 구조(3개 이상의 계층)와 학습 알고리즘을 사용하여 데이터를 학습하고 예측하는 기술이다. 여러 개의 은닉층으로 구성된 신경망 구조를 통해 인간의 뇌를 흉내내어 대량의 데이터로부터 복잡한 특징과 패턴을 학습할 수 있다. 이미지 인식, 음성 인식, 자연어 처리 등의 분야에서 높은 성능을 보이며, 대용량의 데이터와 강력한 컴퓨팅 리소스가 필요하다.
딥러닝은 기계 학습의 한 분야로, 데이터에서 특징(feature)을 추출하고, 이를 기반으로 모델을 구축하며, 학습 데이터를 통해 모델의 가중치(weight)와 편향(bias)을 조정하여 최적의 결과를 얻는 것을 목표로 합니다. 딥러닝에서는 역전파(backpropagation) 알고리즘을 사용하여 모델의 오차를 최소화하는 방향으로 가중치와 편향을 업데이트합니다.
딥러닝은 다양한 응용 분야에서 활용됩니다. 예를 들면, 이미지 인식, 음성 인식, 자연어 처리, 자율 주행, 추천 시스템, 게임 플레이 등 다양한 분야에서 딥러닝 기술이 혁신적인 성과를 이끌어내고 있습니다. 딥러닝은 기존의 전통적인 방법들보다 더 정확하고 복잡한 문제를 다룰 수 있으며, 데이터의 특징을 자동으로 학습하기 때문에 사전에 정의된 특징 추출 방법을 필요로 하지 않습니다.
딥러닝은 대량의 데이터와 강력한 컴퓨팅 리소스가 필요하며, 훈련 시간이 오래 걸릴 수 있습니다. 그러나 최근의 하드웨어 발전과 병렬 처리 기술의 발전으로 딥러닝을 효율적으로 구현하고 활용할 수 있는 환경이 개선되었습니다. 따라서 딥러닝은 인공지능 분야에서 혁신적인 성과를 이끌어내고 있으며, 다양한 문제에 대한 해결책을 제공하고 있습니다.
목차
1. 머신러닝 vs. 딥러닝
1-1. 머신 러닝
1-2. 딥러닝
1-3. 신경망
1-4. 학습 방법
머신 러닝 vs. 딥 러닝
머신 러닝과 딥 러닝은 취급하는 데이터의 유형과 학습 방법으로 구분된다.
머신 러닝
- 주로 labeling된 정형 데이터를 활용하여 예측을 수행
- 특정 특성(feature)이 입력 데이터에 따라 정의되고 테이블로 구성됨 (인간의 개입 있음)
- 비정형 데이터를 사용할 경우에는 이를 정형 형식으로 구성하기 위해 전처리를 거침
딥러닝
- 머신 러닝에 일반적으로 필요한 데이터 전처리 작업 중 일부를 거치지 않아도 됨
- 텍스트와 이미지 같은 비정형 데이터를 수집 및 처리할 수 있음
- 데이터를 구분할 때 필요한 중요 특성(feature)을 스스로 결정할 수 있음
- 경사하강법(gradient descent), 역전파(back propagation) 등을 통해 정확도를 향상함
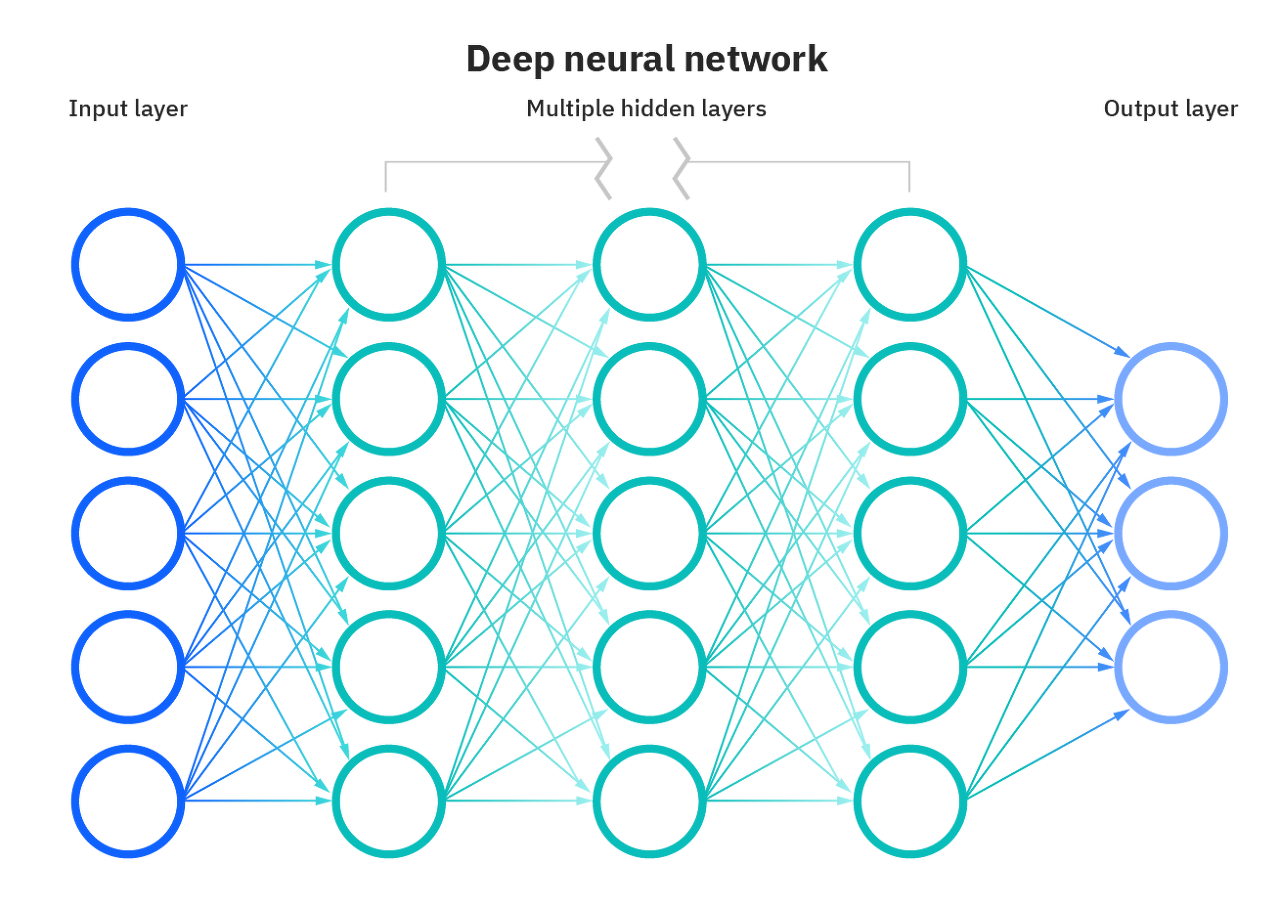
신경망 (Neural Network)
인공 신경망(ANN) 또는 시뮬레이션 신경망(SNN)이라고도 하며, 머신 러닝의 범주에 속하며, 딥러닝 알고리즘의 핵심이다.
이는 일련의 알고리즘을 통해 인간의 뇌를 모방한다.
기본 수준에서 신경망은 input, weight, bias, output의 4가지 주요 구성 요소를 가지며, 하나의 입력 계층, 하나 이상의 은닉 계층 및 하나의 출력 계층을 포함하는 노드 계층들로 구성된다.
기본적인 공식은 다음과 같다.

딥 러닝의 '딥'은 신경망의 레이어 깊이를 의미한다. 입력과 출력을 포함하는 3개 이상의 레이어로 구성된 신경망은 딥 러닝 알고리즘으로 간주될 수 있다.
학습 방법
1. 지도 학습 (Supervised Learning)
- 레이블이 지정된 데이터 세트를 사용하여 정의되는 머신 러닝 접근 방식
- 데이터를 분류하거나 결과를 정확하게 예측하도록 알고리즘을 훈련하거나 "감독(supervise)"하도록 설계됨
- 데이터마이닝 시 두 가지 유형의 문제로 구분할 수 있음
- 분류 (Classification)
- 알고리즘을 사용하여 테스트 데이터를 특정 범주로 정확하게 할당하는 것
- 불연속값(이진 값)을 추정하는 데 사용됨
- ex) 감독 학습 알고리즘을 통해 받은 편지함에서 스팸을 분류할 수 있음
- ex) Logistic regression
- 회귀 (Regression)
- 알고리즘을 사용하여 종속 변수와 독립 변수 간의 관계를 이해하는 또다른 유형의 지도 학습 방법
- 연속적인 값을 예측하는 데 사용됨
- ex) 특정 비즈니스의 판매 수익 예측과 같은 다양한 데이터 포인트를 기반으로 수치 값을 예측하는 데 유용
- ex) linear regression
- ex) 자연어 처리
2. 비지도 학습 (Unsupervised Learning)
- 레이블이 지정되지 않은 데이터 세트를 분석하고 클러스터링함
- 사람의 개입 없이 데이터에서 숨겨진 패턴을 발견 -> (감독되지 않음)
- Clustering, Association 및 Dimensionality reduction의 세 가지 주요 작업에 사용됨
- Clustering
- 레이블이 지정되지 않은 데이터를 유사점 또는 차이점에 따라 그룹화하는 데이터마이닝 기술
- ex) 이미지 압출 등에 유용
- Association
- 주어진 데이터 세트에서 변수 간의 관계를 찾기 위해 다른 규칙을 사용하는 또 다른 유형의 비지도 학습 방법
- ex) 장바구니 분석 및 추천 엔진에 자주 사용됨
- Dimensionality reduction
- 주어진 데이터 세트의 차원 수가 너무 많을 때 사용됨
- 데이터 무결성을 유지하면서 데이터 input 수를 관리 가능한 크기로 줄임
- ex) 인코더가 화질을 개선하기 위해 시각적 데이터에서 노이즈를 제거하는 경우와 같은 데이터 전처리 단계에서 사용됨
지도 학습과 비지도 학습의 주요 차이점
| 지도 학습 (Supervised Learning) | 비지도 학습 (Unsupervised Learning) | |
| 목표 | 새 데이터의 결과 예측 | 대량의 새로운 데이터에서 통찰력 얻기 |
| 응용 | 스팸 탐지, 감정 분석, 일기 예보, 가격 예측 | 이상 감지, 추천 엔진, 의료 영상 |
| 복잡성 | R, python으로 가능할 정도로 간단함 | 대량의 미분류 데이터로 작업하기 위한 강력한 도구 필요. 대규모 train set이 필요하기 때문에 계산적으로 복잡 |
| 단점 | - 시간이 오래 걸림 - input, output에 대한 레이블에는 전문지식 필요함 |
output을 검증하기 위해 사람이 개입하지 않는 한 매우 부정확한 결과 가져올 수 있음 |
3. 준지도 학습 (Semi-supervised learning)
- 지도 학습과 비지도 학습 중 결정할 수 없을 때 준지도 학습 사용
- 레이블이 지정된 데이터와 지정되지 않은 데이터 모두 포함된 데이터 세트를 사용하는 것
- 데이터에서 관련 기능을 추출하기 어렵고 데이터 양이 많을 때 유용
- 사용 이유
- 목표값이 없는 데이터에 적은 양의 목표값을 포함한 데이터를 사용할 경우 학습 정확도에 있어서 상당히 좋아짐
- 목표값을 포함한 데이터를 얻기 위해서는 인간의 개입이 필요한데, 그 비용이 감당할 수 없을 만큼 클 수 있기 때문
- 적은 양의 훈련 데이터로 정확도를 크게 향상시킬 수 있는 의료 영상에 유용
- ex) 종양이나 질병에 대한 CT 스캔의 작은 하위 집합에 레이블을 지정하여 어떤 환자에게 더 많은 치료가 필요한지 기계가 더 정확하게 예측할 수 있음
4. 강화 학습
5. 자기지도 학습(Self-Supervised Learning, SSL)
- 레이블이 없는 데이터가 주어지면, 모델이 학습을 위해서 스스로 데이터로부터 레이블을 만들어서 학습하는 경우
- ex) Word2Vec, BERT
인터넷 자료로 공부하고 정리한 내용입니다.



